AI 绘画的本质是基于概率分布的采样,而非传统的笔触绘制。到 2026 年 3 月,这项技术已从随机的“提示词抽卡”进化为可控的专业工作流,直接改变了商业设计、游戏开发及个人创作的生产效率。
2024 年至 2025 年是 AI 绘画的质变期。早期作品常见的“AI 味”——如手指数量错误或材质光影诡异——在扩散模型(Diffusion Models)迭代后得到显著改善。目前的模型能精准模拟光线在不同材质表面的折射及相机景深。这种演进并非取代绘画,而是像 19 世纪摄影术的出现一样,迫使艺术家从简单的“写实”转向深层的抽象、情感表达和观念创作。
核心原理:潜空间与去噪
主流工具(如 Midjourney v7、Stable Diffusion 3.5)基于潜扩散模型(Latent Diffusion Model)。AI 并非在数据库中“剪贴”图片,而是在训练阶段将图像压缩至低维的“潜空间”(Latent Space),通过加入随机噪声使其混沌,再学习如何剔除噪声还原原图。
当你输入描述词时,AI 在潜空间中定位相关数学向量,从随机噪声图开始,逐步剔除不符合描述的像素点,最终“洗”出图像。由于种子值(Seed)的不同,同样的提示词会产生截然不同的结果。若要实现商业级的可重复产出,必须引入 ControlNet 等插件,通过 Canny 边缘检测或 Depth 深度图为 AI 提供“骨架”约束,避免其在概率分布中盲目漫游。
专业级可控工作流指南
生产环境下的 AI 绘画需遵循:精准定义 $\rightarrow$ 结构控制 $\rightarrow$ 局部精修 $\rightarrow$ 超分放大。
第一步:结构化提示词与权重分配

模糊的描述(如“细节丰富”)对 AI 效果有限。建议采用“主体 + 场景 + 光影/氛围 + 艺术风格 + 技术参数”的结构。
- 主体:使用具体名词。将“一个女孩”改为“一个穿着 2026 年夏季亚麻连衣裙的 20 岁北欧女性”。
- 环境:定义空间关系。如“站在阴雨绵绵的东京涩谷十字路口,周围是半透明全息广告牌”。
- 光影:指定光源和色温。如“侧逆光,冷色调,带有 4000K 街灯漫反射”。
- 参数:在 Stable Diffusion 中,使用
(word:1.2)增加权重,[word]降低权重。
注意:避免提示词冲突(如同时要求“极简”与“巴洛克”),否则 AI 会产生似是而非的中间态。可使用分段提示词或 LoRA 模型分开管理风格。
第二步:使用 ControlNet 强制约束空间结构
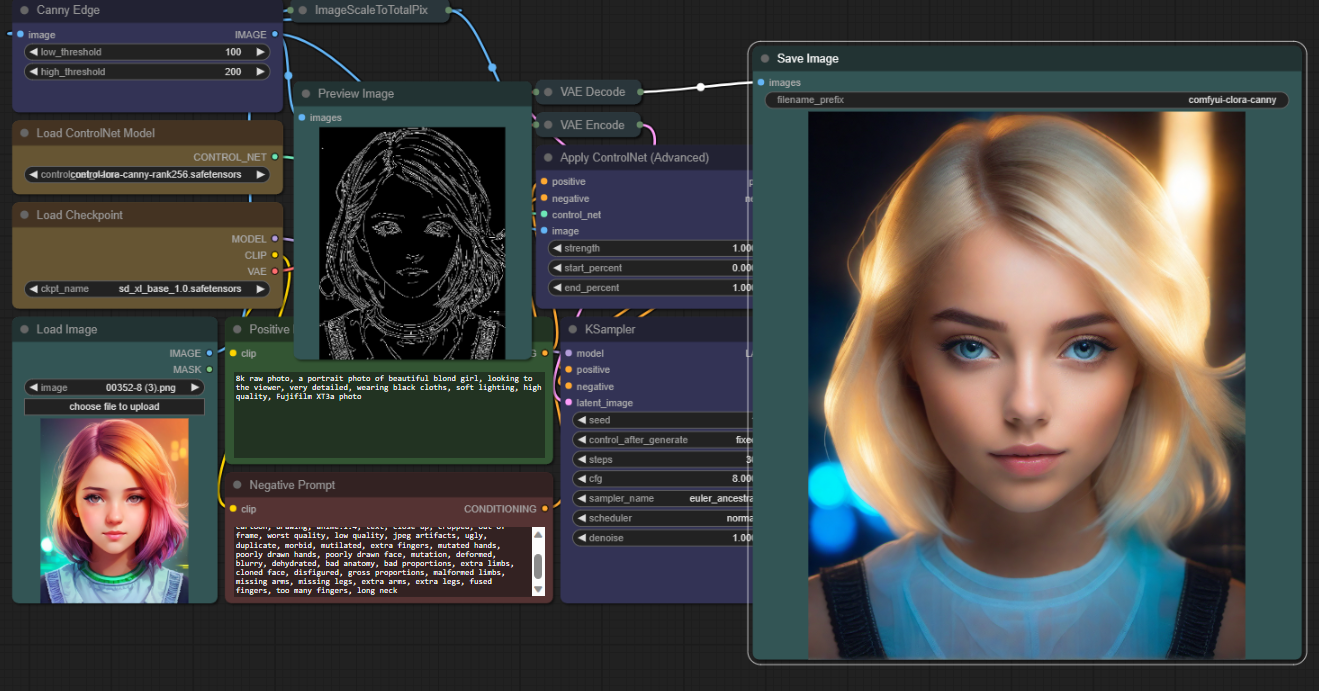
依赖提示词无法精准控制姿势或透视,必须使用 ControlNet。
2. 选择模型:根据需求选择 Canny(边缘检测)或 OpenPose(姿态检测)。
3. 配置参数:Control Weight 设为 1.0,Starting Control Step 为 0,Ending Control Step 设为 0.7。最后 30% 的步骤释放 AI 创造力,使画面自然融合。
若边缘过于死板,可将 Control Weight 降至 0.6-0.8。
第三步:局部重绘(Inpainting)精准修复
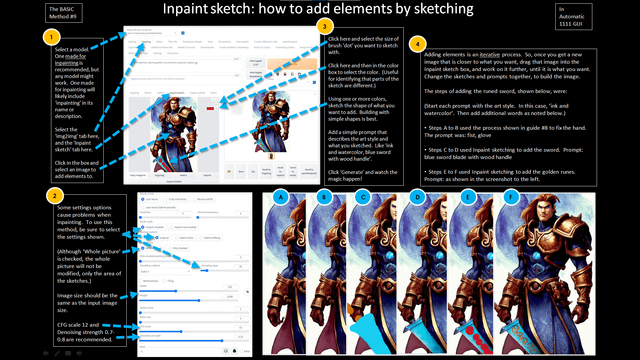
局部重绘是区分业余与专业的关键。将图发送至 Inpaint 界面,用画笔涂黑需要修改的部分(如错误手指)。
第四步:高清放大(Upscaling)与细节增强
针对印刷或 4K 需求,推荐使用 R-ESRGAN 4x+ 或生成式填充放大模型。设置 2x 或 4x 放大倍数,并开启 Tiled VAE 分块处理以防止畸变。最后使用低重绘强度(约 0.2)进行全局重绘,增加皮肤纹理或织物纤维的真实感。
工具选择矩阵

| 工具 | 核心优势 | 局限性 | 适用场景 |
|---|---|---|---|
| Midjourney (v7+) | 艺术感强,电影级光影 | 闭源,精准控制力较弱 | 概念设计、插画初稿 |
| Stable Diffusion | 开源,上限极高,可控性强 | 学习曲线陡峭,需高性能GPU | 商业精准控制、产品设计 |
| Adobe Firefly | 版权合规,集成度极高 | 艺术爆发力相对较弱 | 企业级商用、电商海报修改 |
边界条件与局限性
AI 绘画无法完全取代人类工作流的三个场景:
- 严苛的逻辑一致性:如复杂的工业零件组装图,或同一角色在 50 个不同角度且细节绝对一致的分镜。AI 容易出现“视觉合理但物理不可能”的错误。
- 深层情感与观念表达:AI 倾向于“平均审美”。真正的艺术突破源于对常规的破坏,而 AI 本质是回归概率中心。哲学深度的作品仍需人类定调。
- 像素级品牌资产管理:针对 VI 系统中极细碎的规范(如标志精确倾斜度、特定品牌专色),AI 的随意性无法保证绝对统一。
如何有效避免 AI 生成画面的“塑料感”?
可以通过在提示词中加入具体的材质描述(如 "matte skin texture", "raw linen fabric")并降低重绘强度,或在后期使用低强度的全局重绘增加随机噪点和微小瑕疵,使画面更趋向真实摄影而非过度平滑的数字渲染。
ControlNet 的多种模型可以叠加使用吗?
可以。在 ComfyUI 或 Stable Diffusion 中,你可以同时加载 Canny 约束轮廓和 OpenPose 约束姿态,通过分别调整每个模型的权重(Control Weight)来达到极高精度的空间控制。
进阶行动建议
不要盲目背诵提示词词库。建议按以下路径进阶: